
2025-09-01
New Features
This release introduces:- a new embedding model that enhances textual search, clustering, and mislabel detection capabilities
- a new filter to allow users to filter bounding boxes by object (pixel) size.
New Embedding Model
We are excited to announce the introduction of a new embedding model that expands the way teams can explore, organize, and validate their data. By combining these improvements, the model:- Reduces dependency on expensive infrastructure
- Strengthens insights through better clustering
- Raises the overall trustworthiness of datas through improved quality checks
Textual Search Without GPUs
Until now, running rich text-based searches across large datasets often required specialized hardware such as GPUs and additional compute time. With this release, our model delivers efficient, accurate textual search on standard CPUs, making it easier and more cost-effective to integrate into everyday workflows.
Improved Clustering Capabilities
The new architecture enhances how related items are grouped together, producing clusters that are more coherent and meaningful. This makes pattern discovery faster and the results more reliable, whether you’re mapping themes or identifying anomalies.Stronger Mislabel Detection
Identifying mislabeled data has always been a challenge. This version offers a step forward with sharper, more consistent detection methods, reducing noise and improving dataset quality with less manual intervention.New Filter
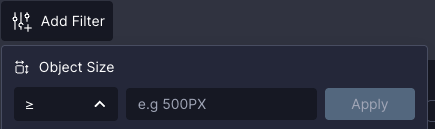
This version introduces a filter by object (pixel) size (width, height).This filter allows users to view only bounding boxes (objects) above/below a specified size (in squared pixels).
Enhancements & Fixes
- Duplicates filter availablity issues after performing a visual search by uploading an external image have been resolved.
- Custom metadata: Increased the enum values limitation from 20 to 100.
- Resolved thumbnail generation inefficiencies from S3 buckets.
2025-05-08
We are excited to present the latest release of Visual Layer. This update introduces powerful new ways to search, explore, and manage visual datasets while streamlining the UI for speed and clarity.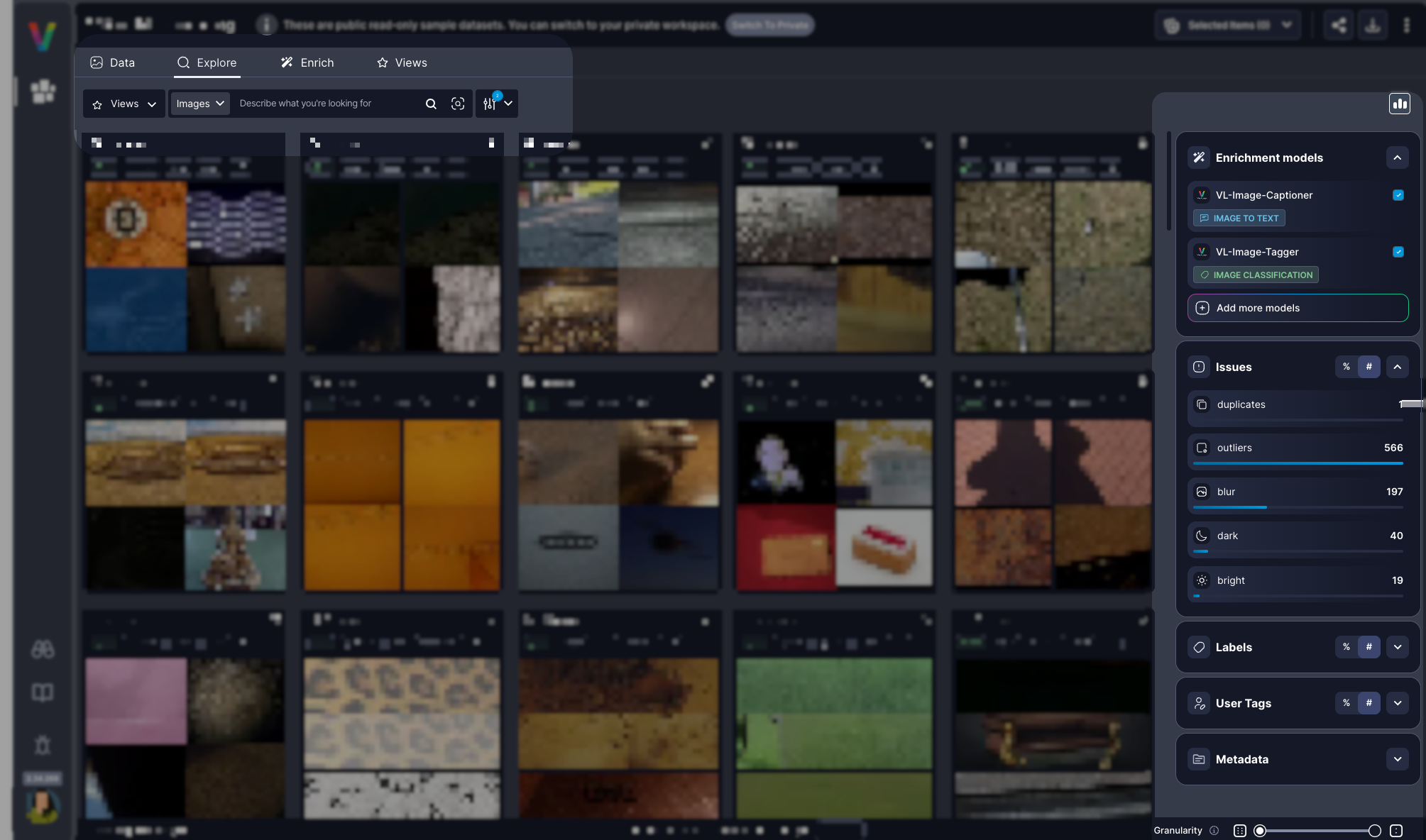
New Features & Enhancements
We’ve overhauled the filtering experience for intuitive navigation, custom quality thresholds, and advanced query logic, making it easier to zoom in on what matters or explore freely at scale.Improved UI Navigation
Filter menu organization and iconography have been updated including a unified slice & dice experience and clearer visual cues for advanced logic combinations.Optimized Filter Logic
Visual Layer now provides logical query operators.We’ve refined the right panel to remove outdated filter controls. Now, you can build filters and review or edit. All applied filters are currently combined using AND logic. Slice and dice your dataset more precisely and seamlessly combine visual and metadata filters for high-volume review.Set flexible conditions per filter type, including:IS, andIS ONE OFIS NOT: Explicitly exclude values and easily remove irrelevant items from your analysisCONTAINSand free-text search that dynamically adapts to your dataset and the current view context
Streamlined Insights
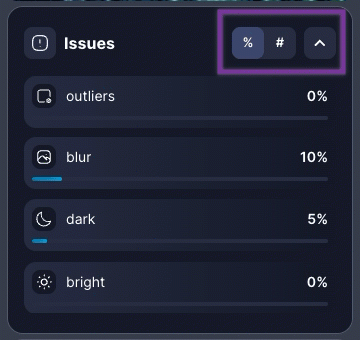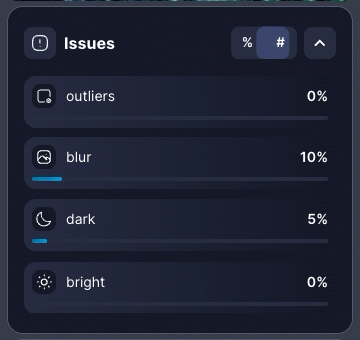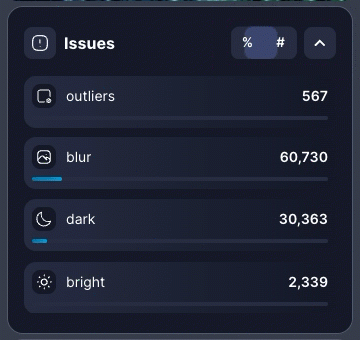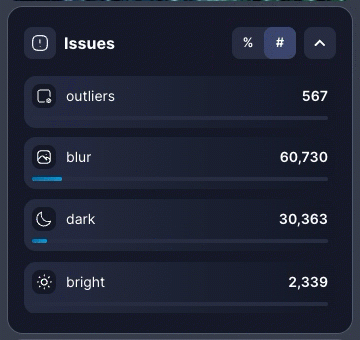
All your dataset insights are now accessible in one place through the redesigned right panel. Easily navigate between statistics, enrichment models, and quality issues without visual clutter. You can also toggle between # (absolute values) and % (relative values) to view data in the format that matters most to you.Class Outlier Detection
Class outliers are a new issue type that help you detect subtle, high-impact inconsistencies in labeled datasets.Unlike mislabels and general outliers, class outliers highlight images that don’t fit the expected structure or semantics of a specific dataset. Class outliers often reflect edge cases, data drift, or content mismatches that can compromise model performance if left unreviewed.You can now:- View class outlier stats in the right panel
- Adjust detection thresholds for both general and class-level outliers WIP
- Filter by outliers or class outliers directly from the main filter menu
Better Documentation to Support You
We’ve upgraded our documentation to make it faster, clearer, and easier to navigate.You’ll notice:- Cleaner layouts that help you focus on what matters
- Collapsible guides and tabs for scanning complex topics
- Inline tips and examples to guide you through advanced use cases
- Mobile-friendly design for quick answers on the go