
Why Unlabeled Data Matters
Unlabeled content is a common byproduct of large, evolving datasets. Whether you’re ingesting new data from external sources or curating internal samples, having a method to quickly surface unlabeled items is essential to improving data coverage and model training effectiveness. Visual Layer makes it easy to locate and take action on unlabeled data—whether at the image or object level.How to Find Unlabeled Data
You can filter for unlabeled content directly within the Visual Layer UI using the “Labels” filter.Steps to Apply the Filter
- Navigate to the Dataset Inventory and click on the dataset you want to review.
- Choose either the Images view or the Objects view.
- In the top filter bar, open the Labels filter.
- Select “Unlabeled” and apply the filter.
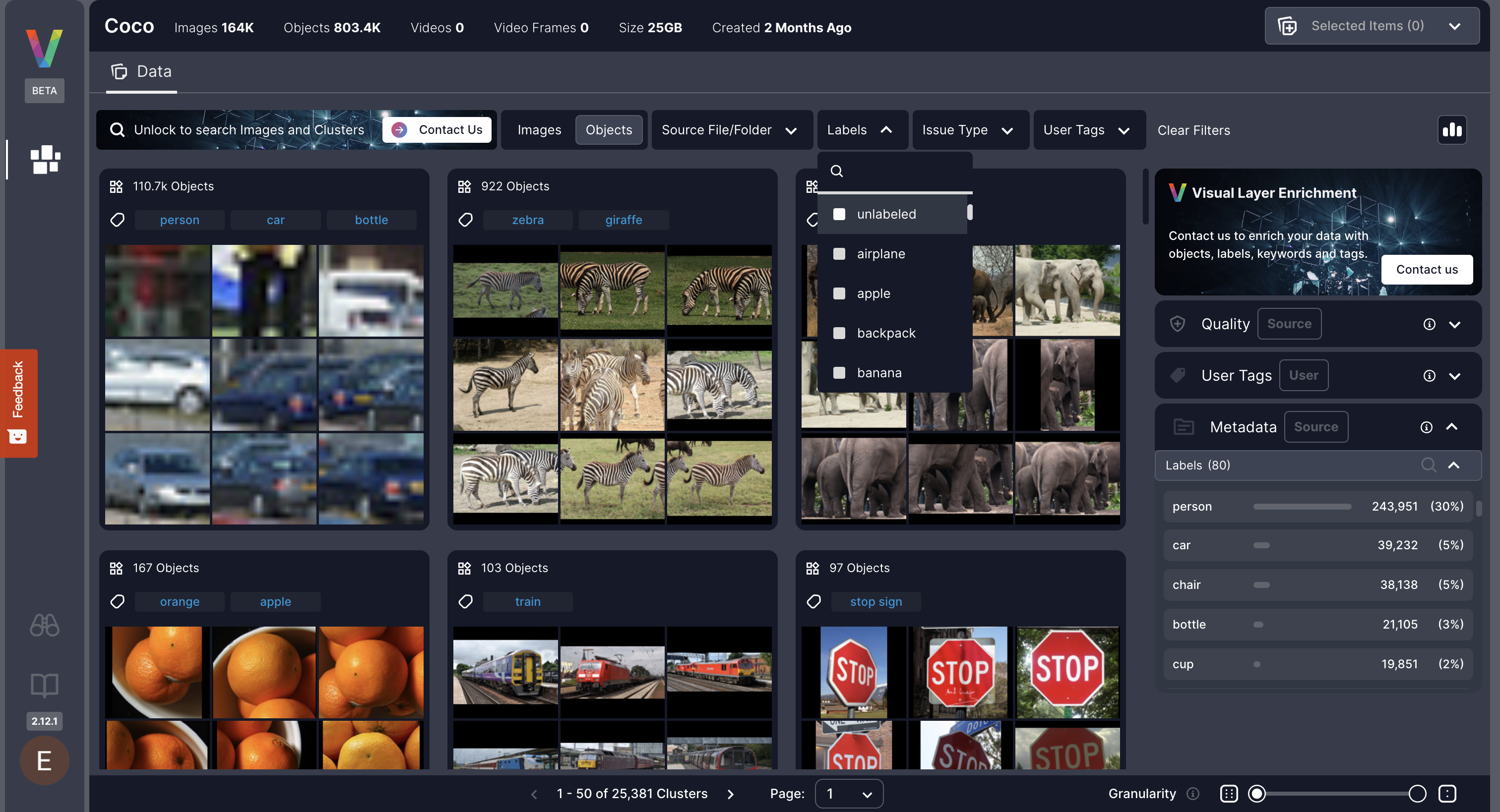
What Happens Next
Once the filter is applied:- You’ll see all images or objects (or clusters) that currently have no label.
- These can be reviewed, grouped, exported, or flagged for labeling.
What You Can Do with Unlabeled Data
After surfacing unlabeled items, you can take additional actions to keep your dataset clean and complete:- Organize: Add relevant data points to the Selected Items list for triage or review.
- Export: Use the Export feature to send selected data for manual annotation, third-party labeling, or internal review.